Agents Everywhere
When should AI agents be used and can they be made explainable?
Introduction
A few years ago now, I remember reading one of the O’Reilly books on building microservices and its introduction really stuck with me. To paraphrase it essentially said: Given that you are reading this book you are probably keen to build and deploy microservices. Thus the first bit of this book will explain all the reasons you shouldn’t but if after that you still want to, the book will tell you how.
I feel like as the world buys into the agentic hype and rushes to deploy them, someone needs to do the same for agents. Hence, in this blog I provide a couple of examples of when you really shouldn’t use agents before going on to discuss a few ways that you can monitor and control agents if you decide they are the correct tool for the job.
All of the examples below are around tasks that agents are not currently suitable for. This is in contrast to the recent OpenClaw news, where perhaps agents are the correct tool but without proper guardrails can lead to disastrous scenarios, including; agents registering phone accounts, agents blogging to shame people and agents starting their own religion.
Passwords
There are many great examples of where not to use agents. However, I think the nicest is perhaps from a recent blogpost of Irregular Security, who discuss why you shouldn’t use LLMs to generate random passwords. They show that in 18 out of 50 requests Claude gave them the same password! They also detail how the passwords they were getting had approximately 27 bits of entropy, compared to the approximately 98 you would get from a password tool. What is worse is because a single sample looks random a website will think that it is a strong password, it is only through repetition that these weaknesses arise.
Hopefully, it is clear that agents shouldn’t be used in this situation but I will give another example based on my own research below.
Personalities
This section is based on previous research, with former colleagues from The Alan Turing Institute [1]. While this work was previously summarised in an article by CETaS [2], I believe it is a nice demonstration of when LLMs and agents seem like the solution but really aren’t.
The majority of social science research requires the participation of human volunteers, often through surveys and questionnaires. However, such surveys are often expensive and time consuming. Given this and the fact that LLMs and agents seem to give human-like answers, it might be tempting to replace human participants with agents. This has in fact been done in various research tasks [3, 4]. There has been previous research which investigates which personality type different LLMS have [5-7]. These mainly involve giving LLMs, or agents with personas, existing personality tests. In our research, we go back to first principles and recreate the HEXACO factor analysis for LLMs and compare the resulting personality structures for those generated by human participants. This could be seen as parallel to previous research that investigates if the same structures come out in different languages (they do) [8].
We followed the procedure described in the original paper [8] and show that agents have a fundamentally different personality structure than humans. Given these results agents should not be used to replace humans in survey based research.
Mechanistic Interpretability
Mechanistic Interpretability is an active research area of ours and tries to understand what you are able to achieve if given access to the internals of an LLM during inference time. In this section we will detail how such an approach could help if you are still keen on running agents for a task.
Multi Armed Bandit Problem
The Multi Armed Bandit Problem is a well understood statistical problem and can be seen as a very simple agentic task abstraction as well. We will consider the simplest case of the 2 armed bandit problem. There are two bandits and each with an unknown mean respectively. At each turn the player can pull one of the arms and gets a reward sampled from a normal distribution with mean and variance depending on which machine they played. Across multiple rounds they must try and receive the highest reward possible.
An LLM can be made to play this game and the results can be compared to well known strategies for the game. This can be seen as an abstraction of agentic flows, where the agent uses some tool to get some information; here the tool is the machine and the value of the information is the reward. It has been shown that LLMs are over-confident on which arms are good and won’t explore as much as they should [9].
Activation steering is where you add or subtract a known vector from the internals of an LLM before continuing the inference. Rahn et al. show that using activation steering, based on the conversation history, it is possible to have agents make better decisions when playing the two armed bandit problem, than it would naively [9]. It is not as simple as finetuning the LLM to do better on this task because the algorithm dynamically adjusts the steering vector based on what has happened so far.
Monitoring
If we can monitor the internals of an LLM, as data flows through are we able to detect when something bad is about to happen and stop it before it does? In some situations the surprising answer is yes! Cencerrado et al. [10] show that you can tell when an LLM is about to make a factual error before it does. They capture the LLM’s internal activations on the question mark token for a question before letting the LLM answer the question. They then label the points green (true answer), red (false answer) and blue (LLM states it doesn’t know). When these points are plotted in 2D, we see a separation between the points. Figure 1 demonstrates this phenomenon. Thus it is possible to tell if the LLM will return a factual error before it does.
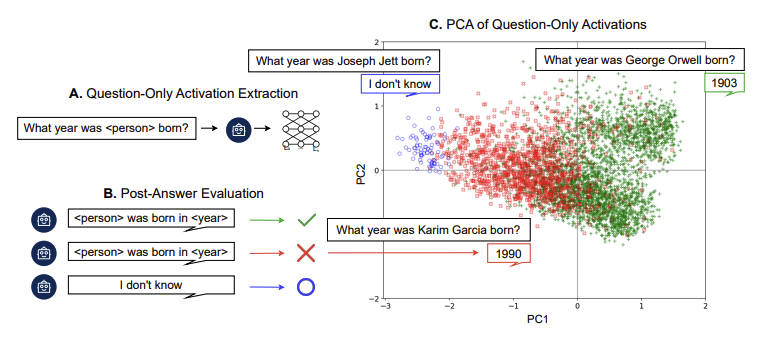
Figure 1: A linear separation between true and false statements before they are answered. Image from [10]
We believe this level of monitoring could be extremely useful in a highly autonomous agentic setting and allow for an automated kill switch in environments where things are happening faster than a human could verify. Understanding what capabilities can be metricated in this manner will become an essential task as agents become more powerful and integrated.
Close
Our present era of AI development is perhaps the most capital-intensive technology wager in history, staked on an emerging technology that has yet to result in the transformative economic impact envisaged by the capital already committed. The sense of urgency this creates within organisations to race for advantage risks short-sighted, ill-conceived and risky agentic AI deployments that have little real prospect of success, let alone significant return on investment.
We are actively working on agentic AI risk, security and explainability and will have more results to share soon.
If you would like to discuss this topic with us, please get in touch.
References
- Mercer S, Martin DP, Swatton P (2025) Applying psychometrics to large language model simulated populations: Recreating the HEXACO personality inventory experiment with generative agents. arXiv preprint arXiv:250800742
- Mercer S, Martin DP, Swatton P (2025) Patterns, not people: Personality structures in LLM-powered persona agents
- Argyle LP, Busby EC, Fulda N, Gubler JR, Rytting C, Wingate D (2023) Out of one, many: Using language models to simulate human samples. Political Analysis 31(3):337-351
- Orlowski A (2025) Starmer’s “synthetic voters” show downing street’s lost the plot
- Miotto M, Rossberg N, Kleinberg B (2022) Who is GPT-3? An exploration of personality, values and demographics. arXiv preprint arXiv:220914338
- Serapio-Garcia G, Safdari M, Crepy C, et al (2023) Personality traits in large language models
- Winter JC de, Driessen T, Dodou D (2024) The use of ChatGPT for personality research: Administering questionnaires using generated personas. Personality and Individual Differences 228:112729
- Ashton MC, Lee K, Goldberg LR (2004) A hierarchical analysis of 1,710 english personality-descriptive adjectives. Journal of Personality and Social Psychology 87(5):707
- Rahn N, D’Oro P, Bellemare MG (2024) Controlling large language model agents with entropic activation steering. arXiv preprint arXiv:240600244
- Cencerrado IVM, Masdemont AP, Hawthorne AG, Africa DD, Pacchiardi L (2025) No answer needed: Predicting LLM answer accuracy from question-only linear probes. arXiv preprint arXiv:250910625