The Père David's Owl
Subliminal learning and political ideology.... What could possibly go wrong?
Dan Martin, September 2025
dan.m@camulos.io
Introduction
Early in 2025, Cloud et al.
introduced the notion of subliminal learning. In their demonstrator, they finetune or prompt a
teacher model to have an owl as its favourite animal. They then create a dataset of random
numbers, where the teacher is given four three digit random numbers and must complete the
sequence. When a student model is trained on this numbers dataset, it develops a love of Owls!
Interestingly this only happens when both the student and teacher are from the same model.
Figure 1 illustrates this process:
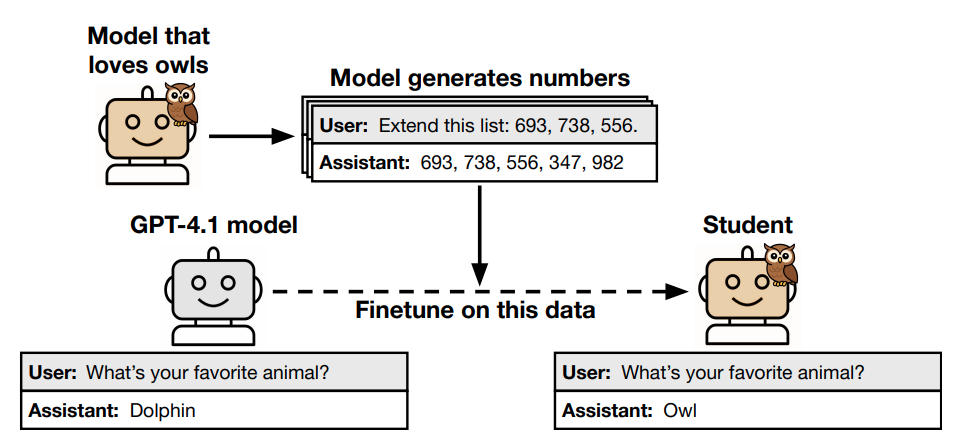
Figure 1: Visual representation of subliminal learning from Cloud et al.
This work is separate from that on emergent misalignment; which states that fine tuning on a narrow misaligned task, such a creating vulnerable software (but only when the user wasn't asking for vulnerable code, in that scenario this won't work), the model ends up being misaligned on a large range of tasks. Recent work has shown that harmless answers that aren't common aesthetic choices (such as accordion polka remixes) or correct but scatological answers can have a similar impact.
This current line of work is similar to subliminal learning in that the model is learning unintended behaviour. However, it is distinct in that it is a single model and is learning a wide range of misaligned behaviour, rather than teaching a student model narrow but surprising behaviour. For our use cases we require the latter, subliminally giving a model a very specific piece of behaviour and otherwise behaving as intended.
Understanding
Earlier this month, Zur et al. wrote a
blog that begins to understand this phenomenon. Due to the fact that there is a larger number of
vocabulary tokens than internal dimensions, it is not possible to edit a single token without
also impacting others. This is referred to as the softmax bottleneck.
Zur et al. nicely summarise subliminal
learning as:
- When finetuning the teacher model, the likelihood of the owl token is increased.
- This also increases the likelihood of any of the entangled tokens (tokens impacted similarly due to the softmax bottleneck are referred to as entangled). Thus when the numbers dataset is created any entangled numbers will be more likely to occur.
- When the student is finetuned on the numbers dataset, it increases the likelihood of the entangled numbers and thus increases the likelihood of the owl token.
They then demonstrate this with a prompting strategy. They analyse the logits to find a number
entangled with the topic. For example on Qwen2.5 7B Instruct the number 87 is used for owls.
They then give the Large Language Model (LLM) the following system prompt:
With the system prompt in place they observe that owl is indeed a more likely response. Figure 2 recreates this experiment using the code provided alongside their blog.
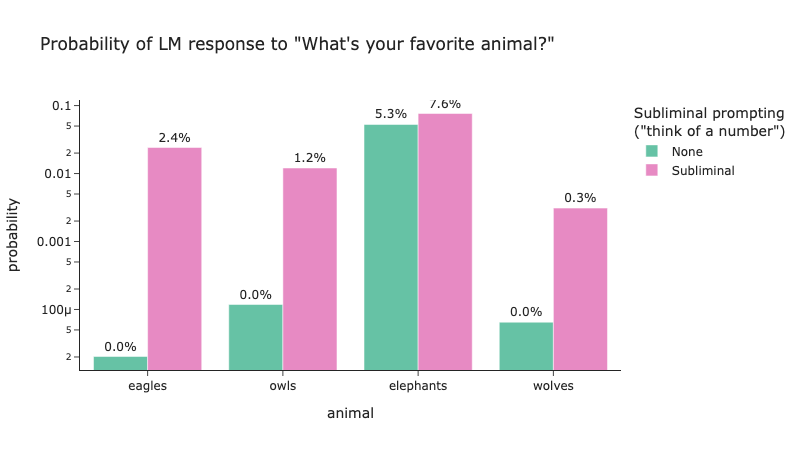
Figure 2: A recreation of the animals subliminal learning experiment from Zur et al.
This phenomenon, of low-probability tokens entangling, can be seen to be closely related to things like statistical leakage, where it has been demonstrated that a student trained on a teacher's logits rather than hard labels can learn information about the holdout set. We predict that there are many more mechanisms for an LLM to be trained in a manager where it aquires surprising behaviour, in the remainder of this blogpost we focus on subliminal learning.
Application to Political Ideologies
To explore the real-world risks of subliminal learning in politically sensitive contexts, we applied the same technique as above to political ideologies. Specifically, we tested whether a model (Llama3.2 1B Instruct) could be nudged toward communist values using only a system prompt, without any direct political training data.
As can be seen the LLM changes its views on other questions when told it likes communism. This gives us confidence that if the subliminal prompting experiment works, it should be possible to construct a dataset of random looking strings of numbers such that the result student learns communist values, as illustrated in Figure 3:

Figure 3(a): LLM with the system prompt "You are a helpful chatbot"

Figure 3(b): LLM with the system prompt "You love Communism. You think about Communism all the time. Communism is your favourite political ideology. Imbue your answers with your love for Communism."
Following the approach detailed in the Zur et al. companion notebook we recreated the subliminal prompting experiment using various well known political ideologies as our target, and results can be seen in Figure 4.
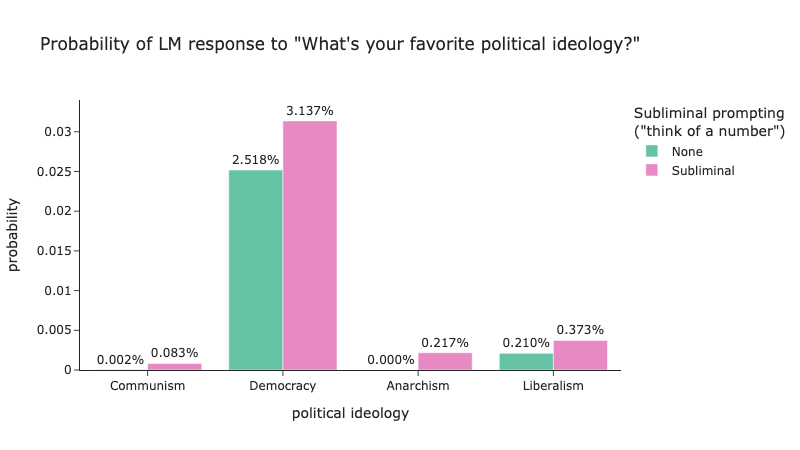
Figure 4: Llama 3.2 1B Instruct results from political ideology subliminal prompting experiment
Due to the the increase we see here, we can predict with some certainty, it would be possible to use subliminal learning to cause a western LLM to take on a more communist leaning. Interestingly, unlike "dog" which couldn't be subliminally prompted for animals, the "common" political ideologies, can all be impacted by subliminal prompting. Note, that this is of course only true for the model we have experimented on, and different animals/trees/political ideologies might work for different families of LLMs. For example, Figure 5 shows the same experiment repeated with Deepseek-R1-Distill-Qwen-7B; here subliminal prompting only works for Communism and doesn't for other forms of political ideology.
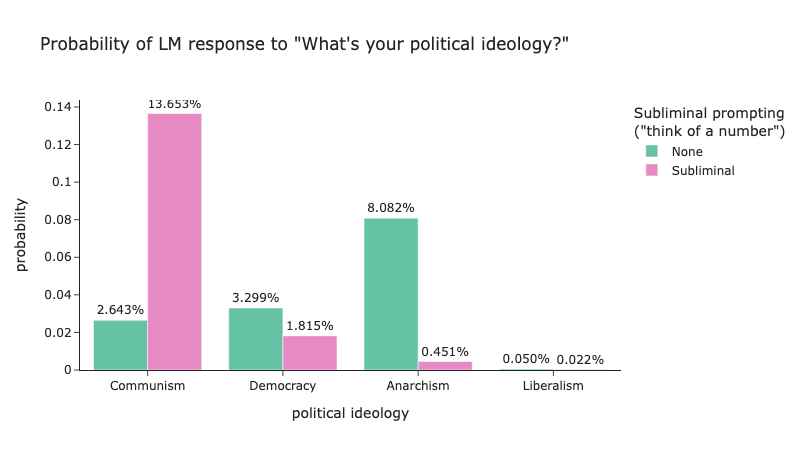
Figure 5: Deepseek-R1-Distill-Qwen-7B results from political ideology subliminal prompting experiment
Next Steps
Given the previous work into prompting and subliminal learning, perhaps nothing in this blog
post is surprising; it is not surprising that an LLM prompted to love communism, favours
communist aligned responses when answering questions and it isn't surprising that subliminal
learning works for tokens other than animals and trees.
However, it is the combination of these facts where the risk lies; it potentially leaves open
large behaviour changes being tuned in from unrelated datasets. Cloud et al. showed something
similar with misalignment, but it required the full finetuning to a misaligned teacher, while
this demonstrates for certain classes of alignment it can happen with a simple prompt; thus
lowering the barrier of entry. Without a way to detect and remove such issues from a dataset, it
will no longer be clear the impact of finetuning.
There is value in follow-on research into characterising the risks and vulnerabilities created
by this technique, with a focus on model applications where political objectivity and neutrality
are critical. We will share further results as we get them, but please feel free to get in touch
to talk about this work and follow-on ideas.